Many wonder how Big Tech became so powerful, wealthy, and leftist. As someone with a technical and C-level management background in the tech business, I can explain. One of the sources of its wealth is wholesale theft of intellectual property by Google and Microsoft’s Bing. Here, the focus is on text-based, non-promotional content produced by “knowledge industries.” The term includes all sorts of publishing from news and commentary to scientific publications.
The main roles in publishing are AUTHOR, PUBLISHER (including editors), DISTRIBUTOR (from wholesalers to local bookstores or paper stands), and USER (buyer and reader).
Google Steals
Let us focus on Google. Google copies all web content that it can reach, then acts as a DISTRIBUTOR of that content, totally ignoring the copyright laws. In response to search words, Google provides links to Google-selected content. Typically, these links are topped by ads, for which Google is paid. Then come sources that Google owns or has business relationships with, such as YouTube, Twitter, or the fake news media. Then there are organic results (“the ten blue links”), also chosen by Google. Google promises its users it will deliver content that is the most useful, relevant, and helpful for them, but does not abide by this promise. However, this is off topic here.
Google makes money when a user clicks on any of the ads, some partner links, or organic results using Google Ads or Google Analytics. Additionally, Google collects information about the user, even if the user clicks on none of the links provided. Thus, Google gets rewarded for its role as a DISTRIBUTOR.
If the user clicks on a third-party link, the third party (publisher or author) must provide the content for the user free of charge (with exceptions for some preferred parties). The user’s visit is the only benefit that the PUBLISHER or AUTHOR gets. Most PUBLISHERs monetize these visits through Google Ads, from which Google takes a large cut and, more importantly, collects information about the website and its visitors. This allows Google to target the visitors with relevant ads on other websites or to re-direct them to competitor’s websites. In other words, Google owns the relationship between the AUTHOR or PUBLISHER and the USER. Thus, the AUTHOR and PUBLISHER must create and publish content as usual, but they receive no compensation. Google gets almost all the money and enormous amounts of personal information. Google shares the loot with Apple (as a search traffic provider), Twitter, and a few others.
USERs have very little choice or control over the content available to them on Google search. Most of them click on one of the top three links, chosen by Google. Of course, no USER can find what Google wants to hide.
Alphabet , the Google’s parent company, makes $200 billion in annual revenue, mostly by monetizing the stolen content (see the line “Google Search & other” in its earnings report), while AUTHORs and PUBLISHERs get close to none.
Publishing Before Google
Compare that with the legal publishing business, which existed before Google’s domination.
An AUTHOR writes a piece and sends it to PUBLISHER(s) of his or her choice. The PUBLISHER chooses from among different AUTHORs and pieces and then prints the selected or combined content, producing magazines and books. For each of these, the PUBLISHER chooses suitable DISTRIBUTORS. Each DISTRIBUTOR also chooses from among different PUBLISHERs and publications. There might be a chain of DISTRIBUTORS, from wholesalers to local booksellers. Then the USER chooses and buys magazines or books. The USER also chooses DISTRIBUTORS (stores) from which to buy. Then the USER pays for the book or magazine, and this payment is split along the production-distribution chain.
The cash flow from buyers to publishers and authors enabled production of quality content. Direct payment by willing readers protected the independence and free speech of publishers and authors.
The Initial Period
Initially, Google did add value. The content was uploaded without commercial intent or was promotional. Much of the valuable content on the Internet was initially placed there by universities and other educational and public authorities, for common use. Google aided users to find what they were looking for. It was fair use of the copyrighted content.
The situation started changing as more valuable content began migrating to the Web. Newspapers started feeling the heat and voicing their concerns about Google around 2009. But the nature of Google’s copyright violation was highly technical, and newspapers did not understand what was happening. It is also possible that the news media elected to stay put because Google was a valuable ally to the Obama administration.
Even before that, Google successfully misled courts into thinking that robots.txt is some kind of a license. No, this file just contains instructions to save resources of both the server and the crawler. Now, Google ignores even robots.txt when it copies copyrighted content. A publisher has no way to prevent copying site’s content by Google without excluding all other search engines. Also, Google search improvements have been perfecting exploitation of stolen content.
No Alternatives
Quality publishing cannot succeed on the Web if Google steals and distributes copyrighted content as if it owns it. This is true for national news and commentary, local news, medical and scientific journals, and everything else. The New York Times and few other apparently successful publications live off crumbs they receive from Google et al.
The ads-based model is not suitable for providing quality content. It compromises visitors’ privacy, allows Google and/or other ad aggregators to target the same visitors anywhere at a fraction of the ad price, and puts the publisher at the mercy of the cancel mob.
In the existing conditions, the paywall model does not work either. Potential readers are unlikely to discover paywalled content. Paywalled content is discouraged by Google. Also, such content or good-enough derivatives can usually be found elsewhere on the Web — with the aid of Google. Conservative websites also face discrimination in Google search.
Fortunately, copyright law is squarely on the side of the authors and publishers—and it has teeth. The rights owner does not need to opt out from Google theft. Google must obtain a license from the copyright owner before copying the content. The solution to Google’s theft exists. When will publishers use it?
By the way, there is an alt-search engine, which is designed to return results from conservative and other Google-suppressed media.
2022-03-05 update
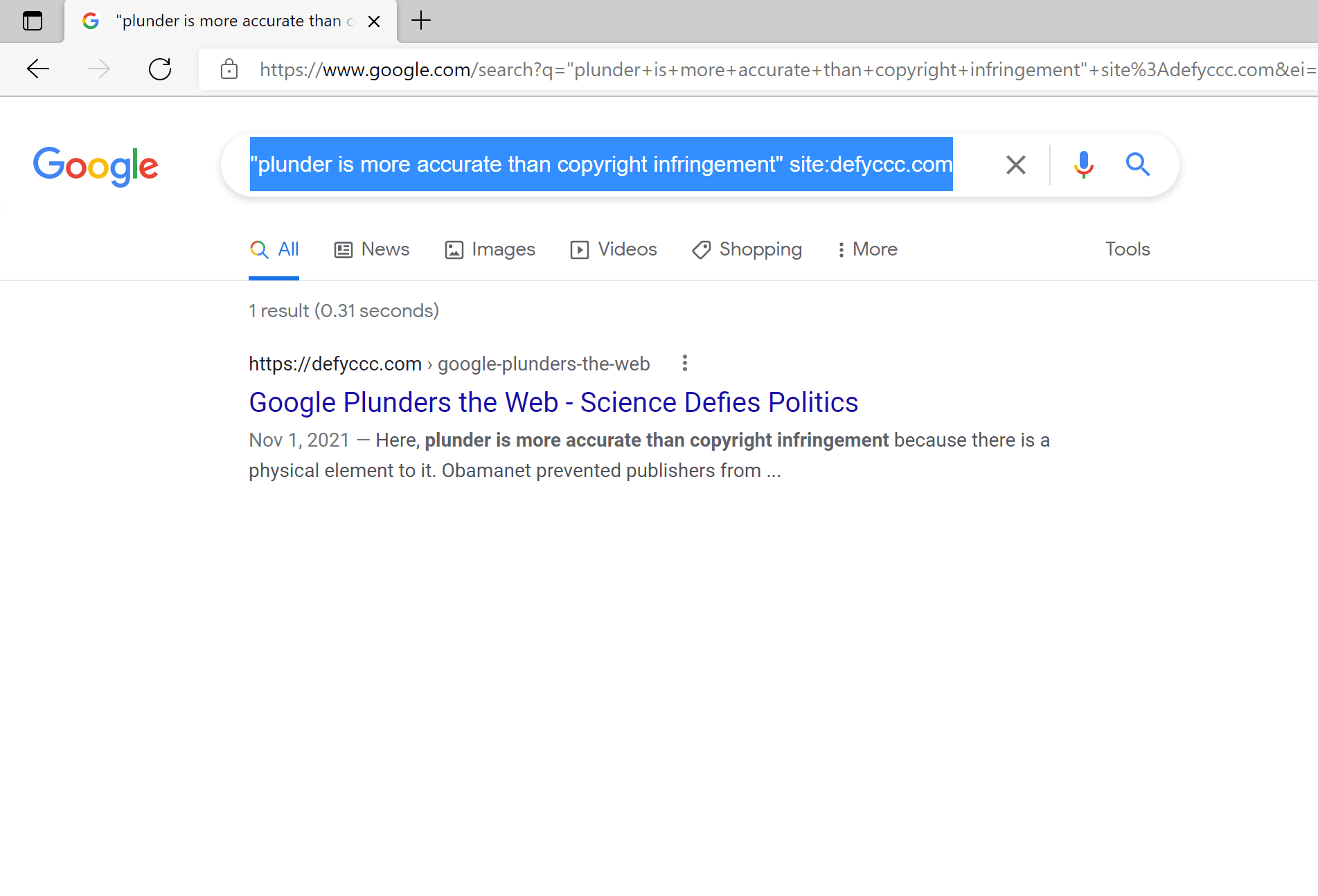
Google’s database contains the full text of each site it indexes. Just type in the Google search a short phrase from your favorite website, and you will see it there. For example, Google search for “plunder is more accurate than copyright infringement” site:defyccc.com returns this phrase with some content around it from this website: